Python登陆小米路由器拨号更换IP,绕过网站反爬IP限制机制
图/文:迷神
最近无聊去爬某眼查的企业数据信息,我已经通过其他方式,把企业数据按照分类和某眼查的属于存到表里面,只要通过某眼查的url地址爬取内容详细页所需要的数据就可以了。但是呢,某眼查作为国内专门抓别人的数据的站,基本上各种反扒机制都有。比如这某眼查如果未登录用户,只能爬100条,超过,立马要求登陆。
有人可能说,怎么不用代理,答案是可以的,但是免费代理,网上一堆免费,但是我实际爬过N多站,基本上100个,能有5个就不错了。大部分都很假,当然土豪也可以去付费去买,然后验证下去买,但是,我们这里借助我们家庭wifi拨号上网模式,只要被限制,立马通过python断网,然后重连,进行更换IP。
Python+小米miwifi路由:
1、获取路由拨号地址
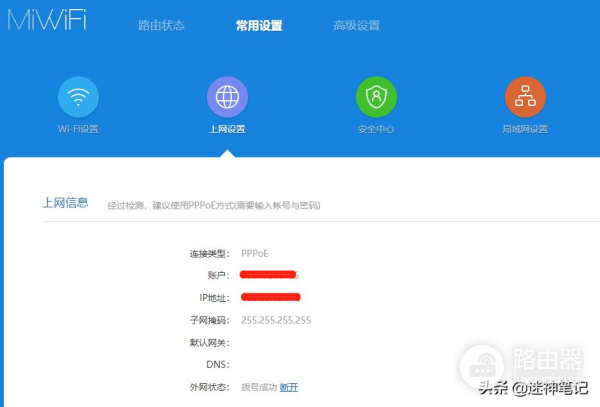
小米路由界面,这里是拨号上网,切换IP
大家可以手动登录下小米路由器(你如果用python等会获取结果一样的,因为这个本地miwifi。com是指向服务器的,可以保持长时间在线的,没必要反复登录,我就不模拟登陆了,都是很easy的事情),可以看到这个拨号联网,是2个开始和暂停js事件,我们只要访问这个地址,即可实现,路由进行拨号上网,即可:
这里我们用到3个类库,先安装下:
pip install pyquery #用于解析某眼查的页面的,非常强大的一个html解析库,有空可以讲讲
pip install requests #页面请求。
pip install retrying #python异常重试类库
爬虫切换路由IP整体思路
1、就是通过数据库,获取某眼查url地址,然后开始爬数据,如果爬取不到想要到的内容,则是被拦截了。
res = mydb.select('url', cond_dict = {'name':'0'},fields=["id", "url"],order="order by id asc limit 1")
id = res[0][0]
url = res[0][1]
print(url)
r = s.get(url,headers=headers, timeout=5)
html = r.text
d = PyQuery(html)
name = d.find('h1.name').text()
if not name:
if html.find('>抱歉,该信息暂不予显示,查一查其它信息<') != -1:
name = '企业异常,不予以展示'
else:
name = ''
print(str(i)+":"+name)
url2 = d.find('a.company-link').text()
print(url2)
if len(name) == 0:
print('被拦截了'+str(i))
else:
update_params = {"name": name,"wz":url2} # 需要更新为什么值
update_cond_dict = {"id": str(id)} # 更新执行的查询条件
mydb.update('url', update_params, update_cond_dict)
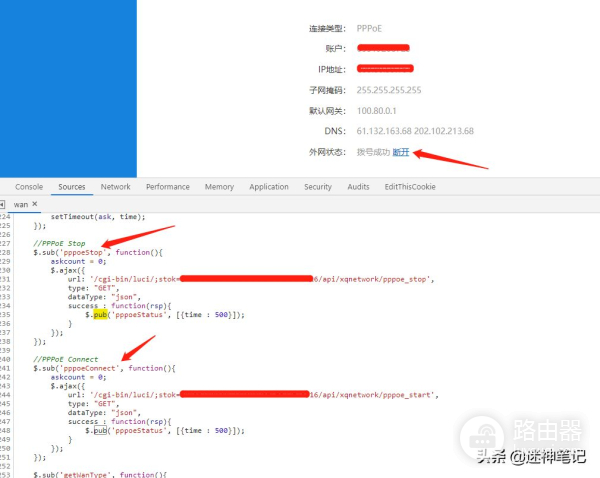
2、调用小米路由器的接口,进行拨号更换,一屏蔽IP,就立马更换IP。
print('开始断网切换IP')
r = s.get("网址/cgi-bin/luci/;stok=固定密钥/api/xqnetwork/pppoe_stop")
for ms in range(10):
print('断网连接'+str(ms)+'秒')
time.sleep(1)
print('开始联网切换IP')
r = s.get("网址/cgi-bin/luci/;stok=固定密钥/api/xqnetwork/pppoe_start")
for ms in range(15):
print('等待联网'+str(ms)+'秒')
time.sleep(1)
3、这里调用retrying模式,就是当出现异常的时候,进行重试,这样就可以实现反复不断的爬取内容,
from retrying import retry
@retry(stop_max_attempt_number=50000,wait_fixed=2000)
def tyc():
#代码
if __name__ == '__main__':
tyc()
最后我们的结果就变成这样了。
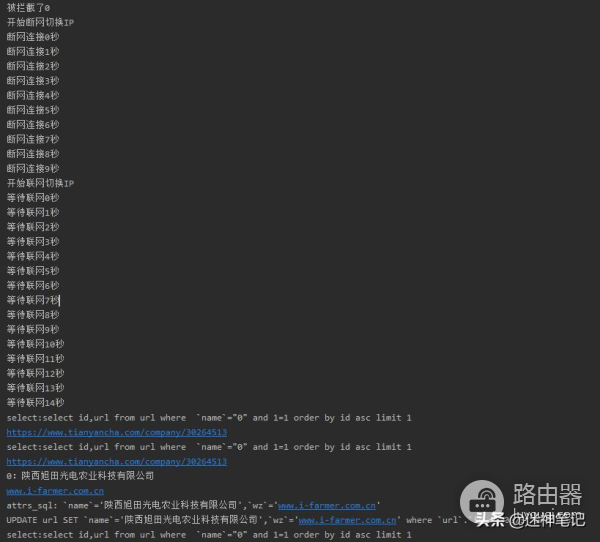
最终结果
这样,就可以不断反复爬数据了,不过,有银子,还是建议买代理吧,一般Vip代理好一点。